인덱스 클러스터링 팩터란?
(실제 사례들을 보며 정리해본 개념)
DB 성능 튜닝 관련 글이나 사례를 보다 보면
“인덱스는 잘 걸려 있는데 왜 느릴까?”라는 질문과 함께 클러스터링 팩터(Clustering Factor) 가 언급되는 경우를 종종 보게 된다.
나는 아직 이 문제를 직접 겪어본 적은 없지만, 여러 DB 튜닝 사례에서 반복적으로 등장하는 개념이라
정확히 어떤 의미이고 왜 중요한지 정리해보고자 한다.
클러스터링 팩터란?
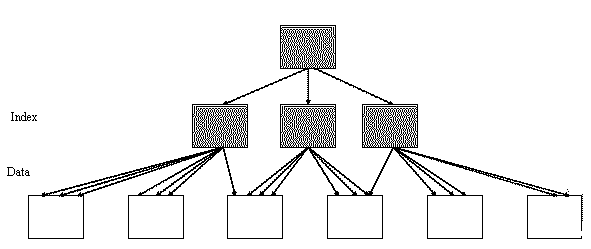
인덱스 클러스터링 팩터(Index Clustering Factor) 는
인덱스 순서대로 데이터를 읽을 때, 실제 테이블 데이터가 얼마나 연속된 블록에 저장돼 있는지를 나타내는 지표
라고 이해할 수 있다.
조금 쉽게 말하면,
- 인덱스를 따라가며 데이터를 읽을 때
- 데이터 블록을 여기저기 이동해야 하면 → 나쁨
- 연속된 블록에서 읽히면 → 좋음
이 “흩어짐 정도”를 숫자로 표현한 것이 클러스터링 팩터다.
왜 중요한가?
실제 사례들을 보면, 다음과 같은 상황에서 문제가 된다.
- 인덱스는 존재하고
- 실행 계획에도 인덱스 스캔이 잡히는데
- 생각보다 성능이 안 나오는 경우
이때 옵티마이저는 단순히 “인덱스가 있느냐”만 보는 게 아니라,
👉 인덱스를 타고 가면 데이터 블록을 몇 번이나 건드려야 하는지
즉, 클러스터링 팩터가 좋은지 나쁜지를 함께 고려한다.
그래서 클러스터링 팩터가 나쁘면 인덱스가 있어도 풀 테이블 스캔이 더 유리하다고 판단하는 경우도 생긴다.
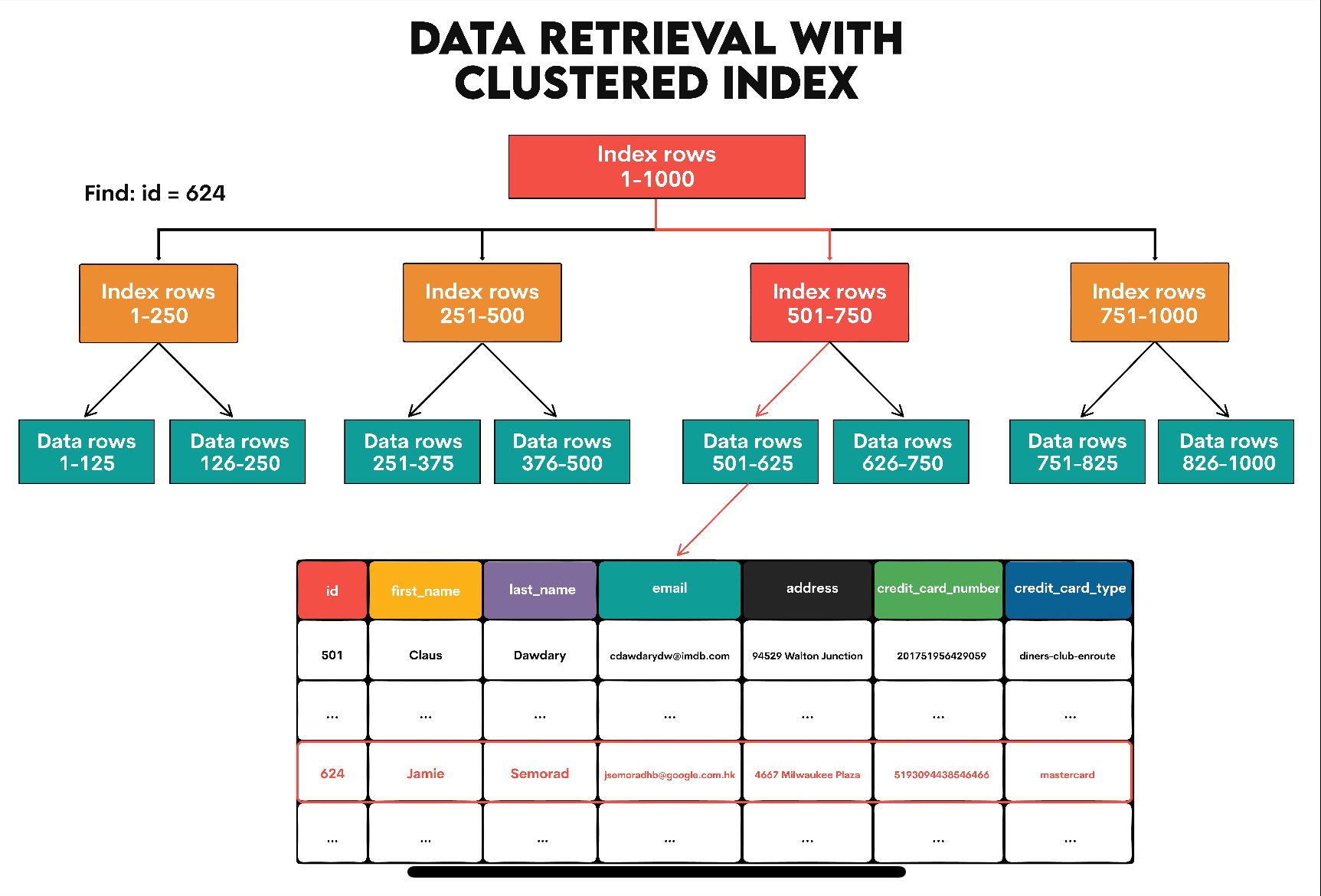
클러스터링 팩터는 어떻게 판단되나?
개념적으로는 다음과 같은 방식이다.
- 인덱스를 리프 노드 순서대로 스캔
- 각 인덱스 엔트리가 가리키는 데이터 블록을 확인
- 이전 행과 다른 블록으로 이동할 때마다 카운트 증가
결국,
인덱스 순서로 데이터를 읽을 때
몇 개의 데이터 블록을 거치는가
가 클러스터링 팩터의 핵심이다.
좋은 값과 나쁜 값의 차이
일반적으로 다음 기준으로 해석된다.
- 테이블 전체 블록 수에 가까움 → 좋음
- 테이블 전체 행 수에 가까움 → 나쁨
예를 들면,
- 테이블 행 수: 1,000,000
- 테이블 블록 수: 10,000
클러스터링 팩터해석
| 12,000 | 매우 좋음 |
| 100,000 | 보통 |
| 900,000 | 매우 나쁨 |
행 수에 가깝다는 건,
👉 인덱스를 따라갈수록 매번 다른 블록을 읽는다는 뜻이다.
클러스터드 인덱스와의 관계
여러 사례를 보면,
클러스터링 팩터 이야기는 클러스터드 인덱스와 함께 자주 등장한다.
- 클러스터드 인덱스
- 데이터가 인덱스 키 순서로 저장됨
- → 클러스터링 팩터가 매우 좋음
- 논클러스터드 인덱스
- 데이터 저장 순서와 무관
- → 클러스터링 팩터가 나빠질 가능성 높음
즉,
인덱스 구조 자체보다도
“데이터가 실제로 어떻게 쌓여 있느냐”가 중요하다는 점이 인상적이다.
실제로 문제 되는 경우
정리된 사례들을 보면 이런 패턴이 많다.
- 특정 컬럼에 인덱스 생성
- 초기에는 성능이 괜찮음
- 데이터가 계속 INSERT / UPDATE 됨
- 시간이 지나면서 데이터가 물리적으로 뒤섞임
- → 클러스터링 팩터 악화
- → 인덱스 스캔 성능 저하
결국 인덱스가 있어도 느려지는 상황이 발생한다.
개선 방법으로 자주 언급되는 것들
사례 기준으로 자주 등장하는 해결책은 다음과 같다.
- 테이블 재정렬
- 인덱스 재생성
- 범위 조회가 많은 컬럼을 기준으로 클러스터링 고려
- 값이 자주 변경되지 않는 컬럼 선택
다만 이 부분은 운영 환경, DBMS 특성에 따라 신중히 판단해야 할 영역이다.
정리하며
이번에 정리하면서 느낀 점은,
- 클러스터링 팩터는 인덱스의 “겉모습”이 아니라 “실제 효율”을 보여주는 지표
- 인덱스가 있는데 느리다면, 단순히 SQL 문제만이 아니라 데이터 물리 구조도 의심해볼 필요가 있음
- 특히 대용량 테이블에서는 시간이 지나며 성능이 변하는 이유를 설명해주는 개념이라는 점에서 중요해 보인다.
아직 직접 겪은 문제는 아니지만, 나중에 성능 이슈를 마주쳤을 때
“아, 이게 그때 봤던 클러스터링 팩터 이야기구나” 하고 떠올릴 수 있도록
미리 정리해두는 의미가 있을 것 같다.
'나의 개발 > 데이터베이스' 카테고리의 다른 글
| 트랜잭션 읽기와 격리 수준 (Isolation Level) 정리 (3) | 2025.12.29 |
|---|---|
| 관계형 데이터베이스(RDB)란 무엇인가? (0) | 2025.12.29 |
| 클러스터드 인덱스란? (3) | 2025.12.26 |
| DB 스키마와 ERD를 설계·확장·운영하려면 어떻게 해야 할까? (요약) (0) | 2025.12.20 |
| DB 스키마와 ERD를 설계·확장·운영하려면 어떻게 해야 할까? (NestJS + TypeORM) (0) | 2025.12.20 |




댓글